
Akida first neuromorphic IP available on the market. Inspired by the biological function of neurons and engineered on a digital logic process, the Akida’s event-based spiking neural network (SNN) performs trillions of operations per second while consuming minimal power. When using the unique BrainChip SNN conversion flow, the event-based nature of SNNs allow converted networks to be implemented with very low power consumption and high throughput. Based on neuromorphic SNNs, Akida’s Neuromorphic IP enables unsupervised learning to support autonomous edge applications. Akida’s Neuromorphic IP can be easily integrated with any ASIC controller via standard AIX bus interfaces.
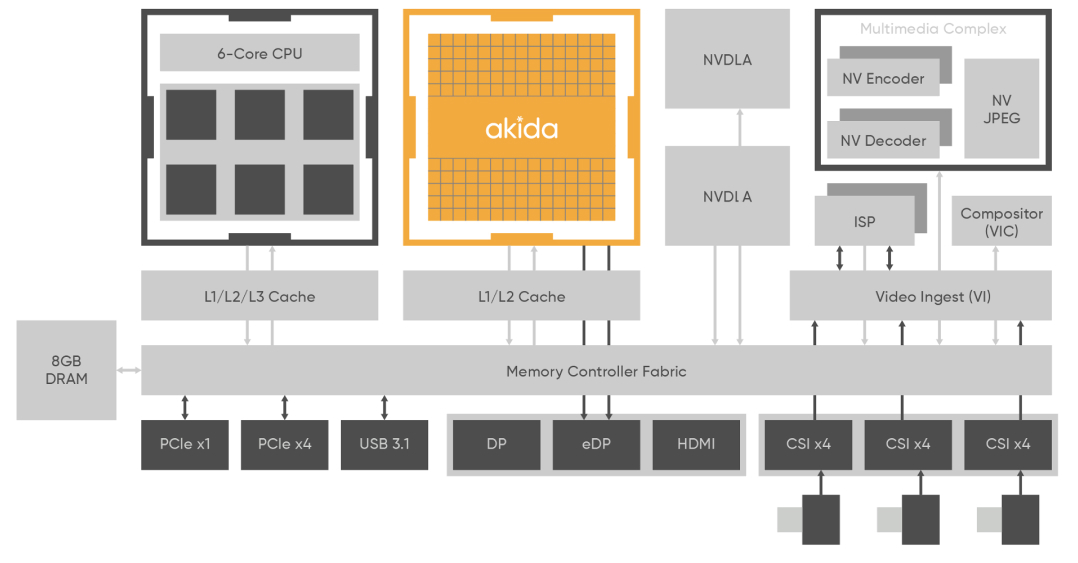
Akida IP Block Diagram
Specifications
Akida Neuron Fabric
- Array of flexible Neural Processing Cores
- Can be arrayed as needed for network sizing
- Interconnect network for spike transmission
- Embedded SRAM
On-Chip Conversion Complex
- Flexible pixel-spike converter for either grey scale or RGB data
- Programmable data-spike converter for all other datatypes
Industry standard interface
- AXI BUS
- DMA engines
- Clock Speed: KHz – 500MHz
- Power Consumption: Can be implemented in mW—no host CPU required to run the network
Area
- Dependent upon NPU array size and technolgy node supported by Akida Development Environment
- SNN conversion flow
- Native SNN flow
Key Features and Benefits
Designed for mW Edge AI Applications
- Simple to complex neural networks at minimum power
- Unsurpassed performance and accuracy
- Edge learning
Flexible Training Methods
- Supports native SNN training
- Supports pre-trained networks such as CNNs
- Data to spike conversion
Scalable Neuron Fabric
- Configurable neurons and synapses
- 1 to 4 bit weights and activations
Technology Independent
- Digital CMOS, no special process elements
- Available as soft IP / RTL
Applications
Edge AI Vision Systems
- ADAS/AV
- Drones/vision guided robotics
- AR/VR
- Video surveillance
- Gesture learning and recognition
- DVS systems
Industrial Internet of Things (IIoT)
- Environmental monitoring/control
- Predictive maintenance
Audio
- Key word spotting
- Vibrational analysis
- Cybersecurity
Consultative Enablement

Highly Configurable
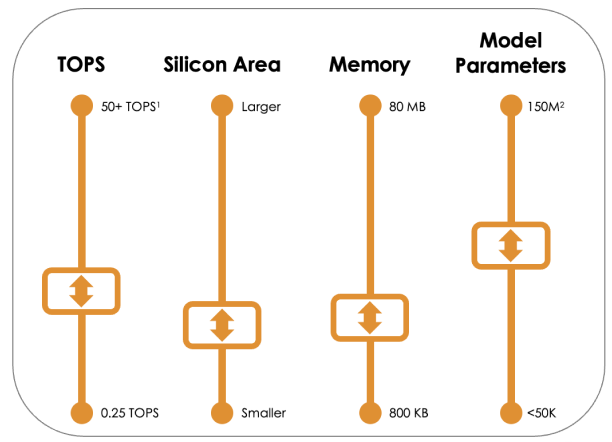
- Brainchip works with clients to achieve the most cost-effective solution by optimizing the node configuration to the desired level of performance and efficiency.
- Scale down to two nodes for ultra low power or scale up to 256 nodes for complex use cases.
- Multi-pass processing provides flexibility to process complex use cases with fewer nodes and increase power efficiency.
- Quantization in MetaTF converts model weights and activations to lower bit format and reduce memory requirements.
